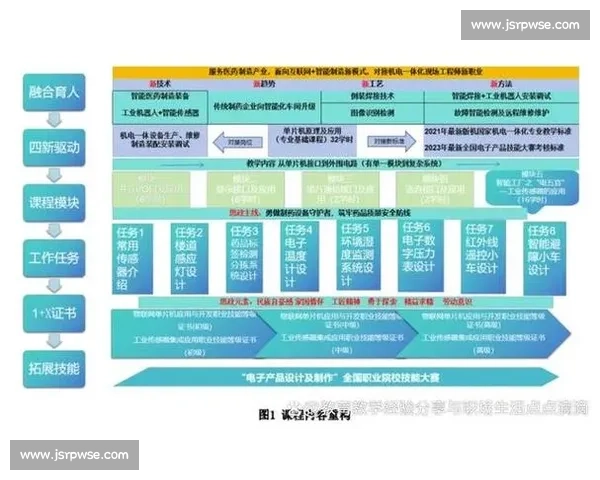
文章摘要的内容:面向复杂场景的深度模型对抗训练关键技术,已成为当前人工智能安全领域的研究热点。随着深度学习模型在自动驾驶、智能安防、医疗诊断、金融风控等高风险场景中的广泛应用,模型在开放环境中面临的对抗攻击、分布漂移与未知干扰问题日益突出。对抗训练作为提升模型鲁棒性的核心方法,通过构造扰动样本增强模型抗攻击能力,但在复杂场景中仍面临泛化能力不足、训练成本高昂以及安全与性能平衡困难等挑战。本文围绕对抗样本生成机制、鲁棒优化方法演进、复杂场景应用实践以及未来发展挑战四个方面,对相关关键技术与研究进展进行系统分析,并深入探讨在多模态、多任务与开放环境下对抗训练的理论突破与工程落地路径,力图为复杂环境中的深度模型安全提供系统化的技术框架与研究思路。
一、对抗样本生成机制
对抗样本生成机制是对抗训练研究的基础,其核心在于通过对输入数据施加微小但具有方向性的扰动,使模型产生错误预测。早期方法以基于梯度的一步或多步攻击为主,通过最大化损失函数来生成扰动样本。这类方法计算效率较高,在图像分类等任务中取得显著效果,但在复杂场景中面对多样化输入与高维数据时,生成策略的有效性与稳定性受到挑战。
随着复杂环境的引入,研究者逐渐关注多样化攻击策略,包括黑盒攻击、迁移攻击以及物理世界攻击等。这些方法突破了白盒假设,使对抗样本更贴近真实应用场景。例如在自动驾驶环境中,通过对交通标志进行物理贴纸干扰即可误导模型判断,显示出对抗样本生成机制从数字空间向现实空间延展的发展趋势。
此外,生成对抗网络等生成式模型被引入对抗样本构造过程中,通过学习数据分布来生成更具隐蔽性与多样性的攻击样本。这类方法提高了攻击的复杂度,也为对抗训练提供了更加丰富的样本空间。然而,如何在保证攻击多样性的同时控制生成成本,仍然是当前研究的重要问题。
在复杂场景下,多模态数据融合使对抗样本生成更为复杂。图像、语音、文本等多种数据形态的联合攻击,需要跨模态扰动设计策略,既要保持单一模态的可控性,又要考虑模态间的协同影响。这种跨模态攻击机制的研究,正在成为对抗样本生成领域的新方向。
二、鲁棒优化方法演进
对抗训练的核心思想可追溯至极小极大优化框架,即在最坏情况下最小化模型损失函数。这种鲁棒优化思想为模型抗攻击能力提供理论支撑。在标准对抗训练中,通过在每个训练批次中加入对抗样本进行迭代更新,使模型逐步适应扰动环境,但其计算开销显著增加。
为提升效率,研究者提出多种加速策略,包括快速对抗训练、样本重用机制以及混合精度计算方法。这些方法在一定程度上缓解了计算负担,使对抗训练能够在更大规模数据集与更深层网络结构中实施。然而,效率提升往往伴随鲁棒性下降,需要在安全与性能之间取得平衡。
近年来,正则化方法与分布鲁棒优化被引入对抗训练框架,通过对输入分布的整体扰动进行建模,提高模型在未知攻击下的泛化能力。这种方法突破了传统基于固定扰动半径的限制,使模型能够在更广泛的环境中保持稳定性能。
同时,自适应对抗训练策略开始受到关注,通过动态调整扰动强度与训练权重,使模型在不同阶段逐步增强鲁棒性。这种分阶段优化思路,在复杂场景下表现出更好的稳定性,但其参数调节机制仍需进一步理论分析与实验验证。

三、复杂场景应用实践
在自动驾驶领域,对抗训练被广泛应用于感知系统的安全加固。车辆在开放道路环境中面临光照变化、遮挡与恶意攻击等多种干扰因素,对抗训练通过模拟这些干扰,提高目标检测与语义分割模型的鲁棒性,为安全行驶提供技术保障。
在智能安防与人脸识别系统中,对抗攻击可能导致身份识别失误,从而产生严重后果。通过引入对抗训练机制,模型在面对伪装、遮挡或微小扰动时仍能保持较高识别准确率。这类实践表明,对抗训练已成为高安全需求场景中的重要技术手段。
在医疗影像分析中,模型需要在复杂噪声与不同设备数据分布下保持稳定性能。对抗训练不仅提升了模型对恶意攻击的抵御能力,也增强了对分布漂移的适应能力,使其在真实临床环境中更加可靠。
此外,在多模态场景如智能语音助手与跨模态检索系统中,对抗训练用于增强模型在语音扰动与文本歧义下的鲁棒性。随着大模型与多模态模型的发展,对抗训练的应用边界正在不断扩展。
四、发展挑战与趋势
尽管对抗训练取得显著进展,但在复杂场景中仍面临多重挑战。首先是计算资源消耗问题,高强度对抗训练需要大量算力支持,在实际部署中成本较高。如何构建高效且可扩展的训练框架,是未来研究的重点方向。
2026世界杯app平台,世界杯APP,世界杯官方下载安装,官方平台,在线观看,World Cup live,世界杯赛程,世界杯视频直播其次,鲁棒性与模型精度之间存在天然权衡关系。过度强调抗攻击能力可能导致模型在干净样本上的性能下降。因此,如何在保证高精度的同时实现强鲁棒性,是当前理论研究的重要课题。
第三,复杂场景中的未知攻击与自适应攻击形式不断演变,传统基于固定扰动假设的训练方法难以覆盖所有风险。未来需要构建更加开放的防御框架,引入自监督学习与元学习思想,提高模型的自适应防御能力。
最后,理论分析仍相对滞后。虽然大量实验结果表明对抗训练有效,但其在高维空间中的收敛性质与泛化边界尚未完全明确。加强理论研究,有助于建立统一的安全评估标准。
总结:
总体来看,面向复杂场景的深度模型对抗训练关键技术正处于快速发展阶段。从对抗样本生成机制的多样化,到鲁棒优化方法的持续演进,再到在自动驾驶、医疗与安防等高风险领域的广泛实践,对抗训练已成为提升模型安全性的核心技术路径。然而,复杂环境中的开放性与动态性,使得对抗训练面临更高的技术门槛与理论挑战。
未来,随着算力提升与算法创新的不断推进,对抗训练将朝着高效化、智能化与系统化方向发展。通过跨学科融合与理论突破,有望构建兼具高精度与高鲁棒性的深度模型安全体系,为人工智能在复杂真实世界中的安全应用奠定坚实基础。